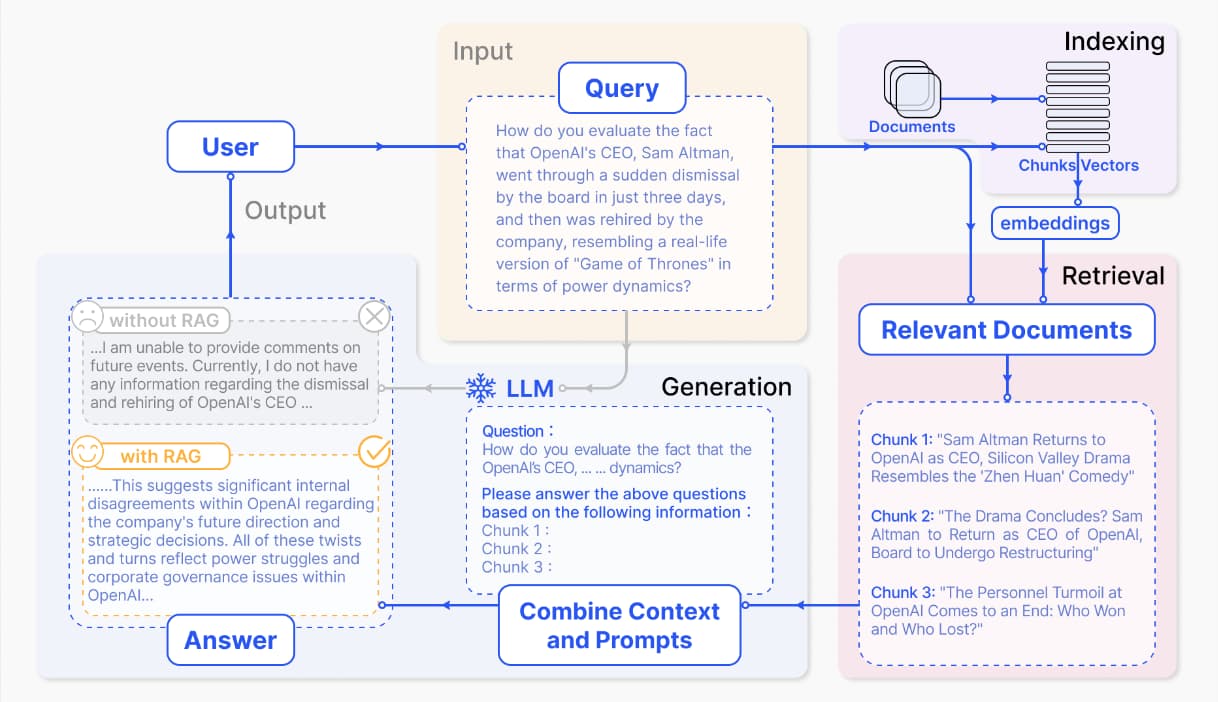
需求
项目目标
构建一个基于大模型微调的AI试题问答系统,支持数学、历史、英语等多学科试题的智能解析、答案生成及知识点关联,适配考试场景的自动评分与错题分析功能。
核心功能需求
试题交互与解析:支持选择、填空、判断、问答等题型交互,自动生成试题解析(含解题步骤与知识点标注)。
智能查询与检索:通过自然语言输入(如“三角函数例题”)或知识点标签快速检索题库试题。
模型微调与优化:基于预训练模型(如DeepSeek、GPT系列)进行领域微调,适配教育场景的术语与逻辑表达。结合试题数据特性优化模型输出,提升答案准确性(如数学公式解析、历史事件时序推理)。
考试与评估模块:支持限时答题、自动评分(客观题)及人工评卷(主观题)。生成多维考试报告,包括得分率、高频错题统计与知识点掌握度分析。
技术实现路径
数据预处理:清洗试题数据,构建结构化题库(含题干、答案、解析、知识点标签)。
模型微调:使用领域数据(如学科教材、历年真题)微调模型,提升学科知识理解能力。
检索增强:结合Elasticsearch等工具实现试题快速召回,优化响应效率。
预期效果:实现试题问答准确率≥95%(进度指标>95%),响应时间≤2秒。通过AI辅助降低教师出题与评卷工作量,提升学生自主学习效率。
数据
数据包含两个部分:问题、答案
根据真实数据的情况,制定数据格式化方案
题目重合、题目(答案)错误
转化为模型可使用的数据格式
题库原始文件,包含题目、答案、解析
9.下列关于生态位的叙述错误的是
A.生态位是一个物种在生态系统中的角色和地位
B.生态位是一个物种对生态环境的适应和调节
C.同一生态位的物种之间会发生竞争和协作
D.生态位的大小是由物种的生物学特性和环境因素共同决定的
答案】B
解析】生态位是一个物种在生态系统中的角色和地位,是该物种在生态系统中所占据的一种生态位,与适应和调节无关。同一生态位的物种之间会发生竞争和协作,包括资源竞争和互利共生。生态位的大小是由物种的生物学特性和环境因素共同决定的,包括食性、生活性、生殖方式、生长速度、竞争力等因素。【详解】A正确;B错误;C正确;D正确。【点睛】生态位是一个物种在生态系统中的角色和地位,是该物种在生态系统中所占据的一种生态位;同一生态位的物种之间会发生竞争和协作;生态位的大小是由物种的生物学特性和环境因素共同决定的,包括食性、生活性、生殖方式、生长速度、竞争力等因素。拿到最原始数据之后,需要对原始数据根据数据格式化模版进行格式化处理,不可避免的需要大量的人力资源进行数据的格式化处理,当然也可以利用大模型处理,模型处理之后依旧需要人工进行审核。可以参考以下Hugginface中数据集格式:
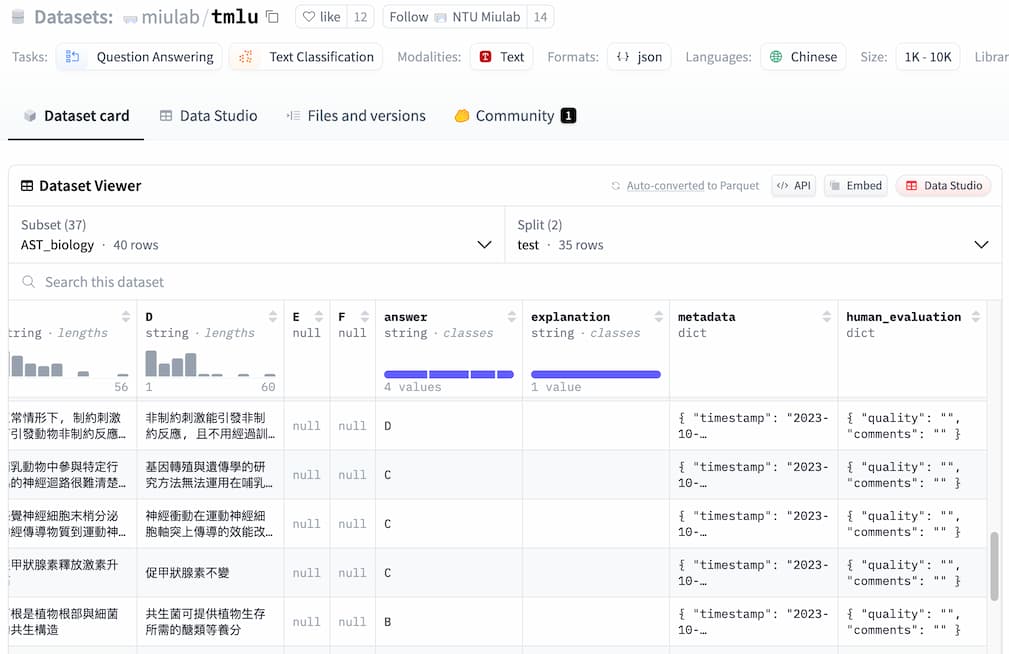
{"id": "AST_chemistry_dev-110-6", "question": "下列有關各物質的分子間主要作用力的敘述, 何者正確?", "A": "$\\mathrm{C}_{2} \\mathrm{H}_{4}$ 主要作用力為共價鍵", "B": "Xe主要作用力為分散力", "C": "$\\mathrm{HCl}$ 主要作用力為離子鍵", "D": "$\\mathrm{BF}_{3}$ 主要作用力為偶極-偶極作用力", "E": "$\\mathrm{H}_{2}$ 主要作用力為氫鍵", "F": null, "answer": "B", "explanation": "1. $\\mathrm{C}_{2} \\mathrm{H}_{4}$為非極性分子,分子間主要作用力為分散力,故(A)錯誤。\n2. Xe 為非極性分子,分子間主要作用力為分散力,故(B)正確。\n3. $\\mathrm{HCl}$ 為極性分子,分子間主要作用力為偶極-偶極力,故(C)錯誤。\n4. $\\mathrm{BF}_{3}$為非極性分子,分子間主要作用力為分散力,故(D)錯誤。\n5. $\\mathrm{H}_{2}$為非極性分子,分子間主要作用力為分散力,故(E)錯誤。", "metadata": {"timestamp": "2023-10-16T22:04:54.555561", "source": "AST chemistry - 110", "explanation_source": "https://www.ehanlin.com.tw/event/pre-exam/download/index.html#AST"}, "human_evaluation": {"quality": "", "comments": ""}}
图形的处理:题目中图形不参与AI的处理;答案中包含图形时,集成生图API或者给图形单独存储,具体题目中图片替换为字符标记,在题目展示时通过标记查询图片。
题目重合:删除重合题目,不做任何处理。
题目答案错误:人工审核
给模型输入:序号、问题,模型输出:答案、解析
数据转换
import csv
import json
import os
# 指定包含CSV文件的目录
csv_directory = 'mydata'
# 输出的JSON文件路径
json_filepath = 'train.json'
# 读取CSV文件并转换为JSON格式
def csv_to_json(csv_directory, json_filepath):
data = [] # 初始化一个空列表来存储转换后的数据
# 遍历目录中的所有文件
for filename in os.listdir(csv_directory):
if filename.endswith('.csv'):
csv_filepath = os.path.join(csv_directory, filename)
try:
# 尝试使用UTF-8编码打开CSV文件
with open(csv_filepath, mode='r', encoding='utf-8') as csvfile:
csvreader = csv.DictReader(csvfile)
# 遍历CSV文件中的每一行
for row in csvreader:
# 将CSV行转换为字典,并添加到数据列表中
data.append({
"instruction": row['题目(含完整选项)'],
"input": "",
"output": row['答案']
})
except UnicodeDecodeError:
# 如果UTF-8编码失败,尝试使用GBK编码
with open(csv_filepath, mode='r', encoding='gbk') as csvfile:
csvreader = csv.DictReader(csvfile)
# 遍历CSV文件中的每一行
for row in csvreader:
# 将CSV行转换为字典,并添加到数据列表中
data.append({
"instruction": row['题目(含完整选项)'],
"input": "",
"output": row['答案']
})
# 将数据列表转换为JSON格式,并写入文件
with open(json_filepath, mode='w', encoding='utf-8') as jsonfile:
jsonfile.write(json.dumps(data, ensure_ascii=False, indent=4))
# 调用函数
csv_to_json(csv_directory, json_filepath)
[
{
"instruction": "下列关于细胞结构和功能的叙述,正确的是( ) A. 有内质网的细胞不一定是真核细胞 B. 有中心体的细胞一定是动物细胞 C. 有高尔基体的细胞不一定有分泌功能 D. 有核糖体的细胞一定能合成分泌蛋白",
"input": "",
"output": "C"
},
{
"instruction": "下列关于酶的叙述,错误的是( ) A. 酶的化学本质都是蛋白质 B. 酶是活细胞产生的具有催化作用的有机物 C. 酶的活性受温度和pH等因素的影响 D. 同一种酶可存在于分化程度不同的活细胞中",
"input": "",
"output": "A"
},
......
]从训练集中随机选择生成测试集
import json
import random
# 指定输入的JSON文件路径
input_json_filepath = 'train.json'
# 指定输出的JSON文件路径
output_json_filepath = 'test.json'
# 指定选择数据的比例因子(例如,0.1表示选择10%的数据)
selection_ratio = 0.3
# 从JSON文件中读取数据
def read_json_file(filepath):
with open(filepath, 'r', encoding='utf-8') as file:
return json.load(file)
# 将随机选择的数据写入新的JSON文件
def write_random_data_to_json(random_data, filepath):
with open(filepath, 'w', encoding='utf-8') as file:
json.dump(random_data, file, ensure_ascii=False, indent=4)
# 主函数
def main():
# 读取JSON文件中的所有数据
all_data = read_json_file(input_json_filepath)
# 计算要选择的数据数量
number_of_items_to_select = int(len(all_data) * selection_ratio)
# 随机选择指定数量的数据
random_data = random.sample(all_data, number_of_items_to_select)
# 将随机选择的数据写入新的JSON文件
write_random_data_to_json(random_data, output_json_filepath)
# 调用主函数
main()
方案
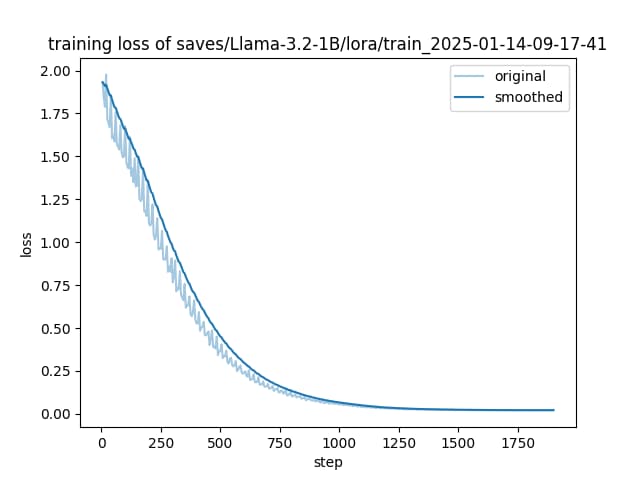
题目的数量非常大,并且每个题目的长度不是特别长,使用RAG时题目数量多,每道题就是一个单独的节点,效率低。题库的问题比较专业,base模型也不一定能够正确理解问题的需求。因此,这里使用微调实现。
针对题库不会频繁更新,并且对精度要求较高,因此此处更偏向于过拟合(模型在当前数据范围内的表现会和标签高度一致)版本。
数据划分规则
训练集包含所有数据,测试集直接从训练集中随机筛选一部分。在训练过程中高度依赖精度指标,判断模型是否达到训练的预期目标。
模型训练到什么时候
只要损失在下降就继续训练,过程中可以使用全部数据集进行测试,如果存在错误推理则可以继续训练。
模型选择
数据越小,模型越大,越“容易”过拟合;反之越不容易过拟合。模型越小,越容易训练、模型越大,训练时间越长。因此,选择BASE模型时不要选的过大,够用就行。形象理解就是模型越大,智商越高,要改变它难度就越高。在当前项目中,我们训练的时Lora部分,我们应该选择个较小的base模型,和一个较大的LoAR模型,使其更容易达到我们想要的效果。理根的模型应该是模型参数小,但是本身的效果很好。
1.5B~3B参数的较小模型在有限数据下更易收敛,且训练时间更短,适合显存资源受限的场景,大模型(如8B参数)在数据量不足时容易捕捉训练数据中的噪声而非真实规律。优先选择“效果足够但参数量较小”的BASE模型,例如3B参数模型。其优势在于:降低显存占用,适配多卡并行训练需求;减少训练时间,提升迭代效率。
Easy sample(模型快速学习的样本)可用于早期快速收敛,而Hard sample(需反复学习的样本)对模型能力提升更关键。通过动态筛选高影响力样本(如LIM方法),可提升训练效率并减少冗余计算。
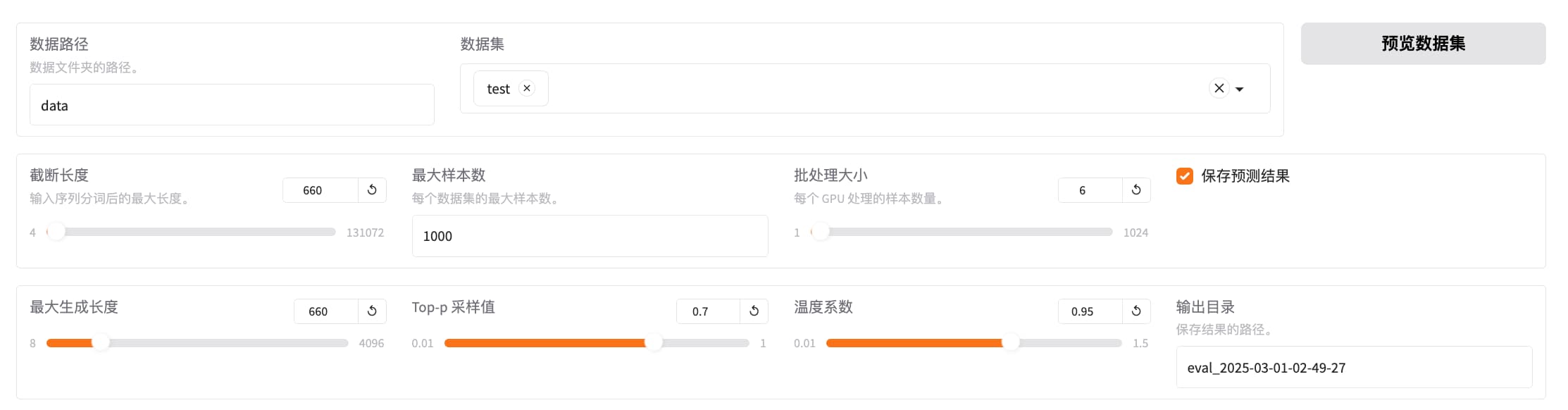
训练、评测
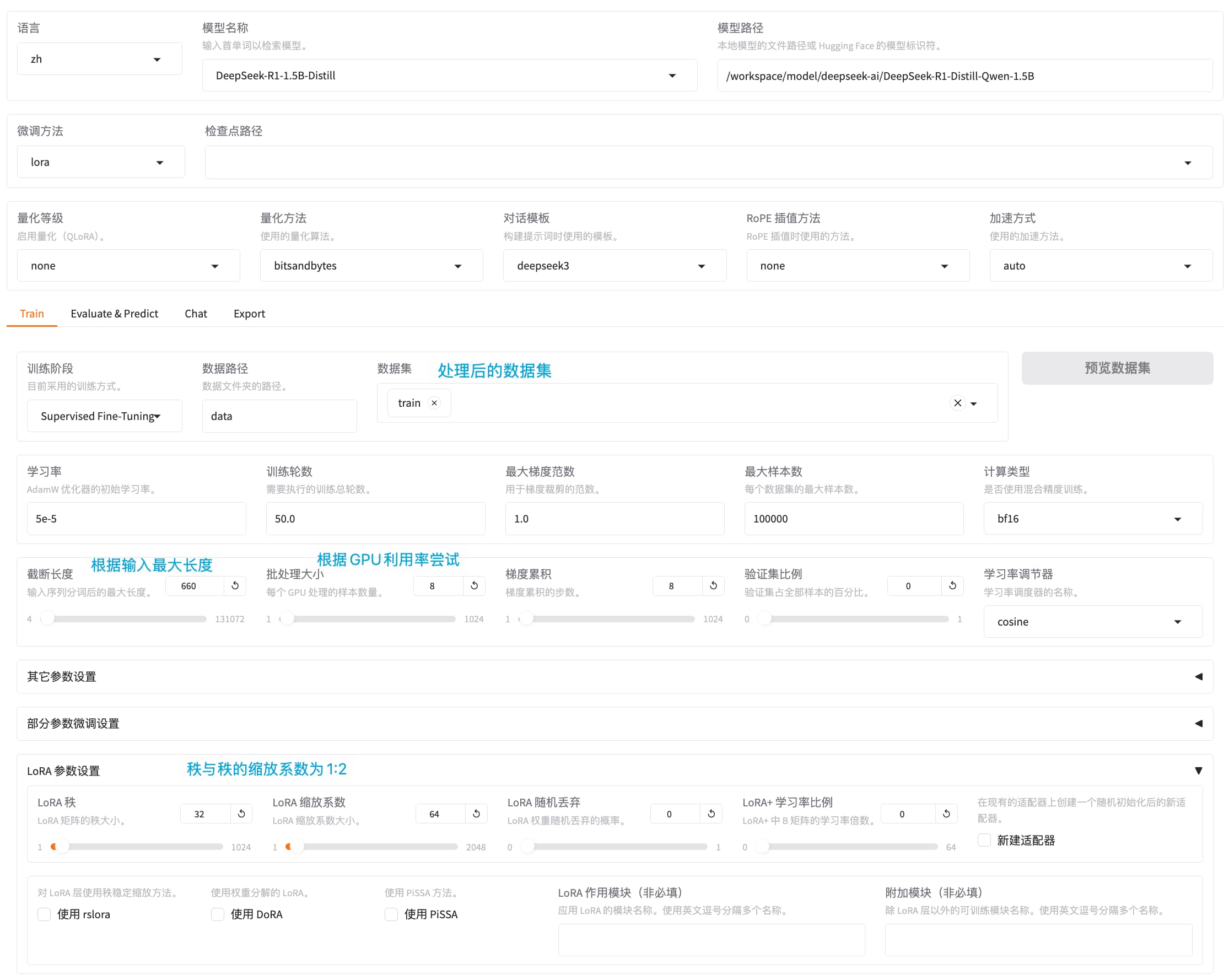
评测
predict_bleu-4 = 67.6777 # 模型生成的文本在四元语法上的匹配程度较高,但仍有改进空间。
predict_model_preparation_time = 0.006 # 非常短,模型加载和初始化非常高效。
predict_rouge-1 = 100.0 # 模型生成的文本在单个词上的匹配非常完美
predict_rouge-2 = 50.0 # 模型生成的文本在双词上的匹配程度一般,需要改进。
predict_rouge-l = 100.0 # 模型生成的文本在最长公共子序列上的匹配非常完美
predict_runtime = 0:05:46.71 # 整个预测过程花费的时间较长
predict_samples_per_second = 0.156 # 处理速度较慢,需要优化
predict_steps_per_second = 0.026 # 处理速度较慢,需要优化
部署
模型合并Lora

vllm部署模型
提示词模板:是一个规范,规定模型应该如何输出内容。
在微调训练或者部署调用任何一个大模型时,都要提供一套提示词模板(对话模板),目前所有的开源大模型都是自带了对话模板的。
注意:微调时使用的提示词模板必须得和部署/推理时使用的提示词模板一致。如果不一致,一般Lora微调的效果表现会很差。
# mytest.py
import sys
import os
# 将项目根目录添加到 Python 路径
root_dir = os.path.dirname(os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))))
sys.path.append(root_dir)
from llamafactory.data.template import TEMPLATES
from transformers import AutoTokenizer
# 1. 初始化分词器(任意支持的分词器均可)
tokenizer = AutoTokenizer.from_pretrained("/root/autodl-tmp/llm/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B")
# 2. 获取模板对象
template_name = "qwen" # 替换为你需要查看的模板名称
template = TEMPLATES[template_name]
# 3. 修复分词器的 Jinja 模板
template.fix_jinja_template(tokenizer)
# 4. 直接输出模板的 Jinja 格式
print("=" * 40)
print(f"Template [{template_name}] 的 Jinja 格式:")
print("=" * 40)
print(tokenizer.chat_template)为了使语言模型支持聊天协议,vLLM 要求模型在其 tokenizer 配置中包含一个聊天模板。聊天模板是一个 Jinja2 模板,它指定了角色、消息和其他特定于聊天对 tokens 如何在输入中编码。
一些模型即使经过了指令/聊天微调,仍然不提供聊天模板。对于这些模型,在 --chat-template 参数中手动指定聊天模板的文件路径或字符串形式。如果没有聊天模板,服务器将无法处理聊天请求,所有聊天请求将出错。
vllm serve /workspace/model/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B-merged --chat-template /workspace/tiku/code/deepseek.jinjaOpen-WebUI连接服务
export HF_ENDPOINT=https://hf-mirof.com
export ENABLE_OLLAMA_API=False
export OPENAI_API_BASE_URL=http://127.0.0.1:8000/V1
open-webui servefrom openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1/",api_key="123")
responce =client.chat.completions.create(
messages= [{"role":"user","content":"下列关于群落结构的叙述,正确的是( ) A. 群落的垂直结构是指群落中不同种群在垂直方向上的分层现象 B. 群落的水平结构是指群落中不同种群在水平方向上的镶嵌分布 C. 动物在群落中的垂直分布与植物的分层现象无关 D. 群落的结构只包括垂直结构和水平结构"}],model="/workspace/model/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B-merged"
)
print(responce.choices[0])