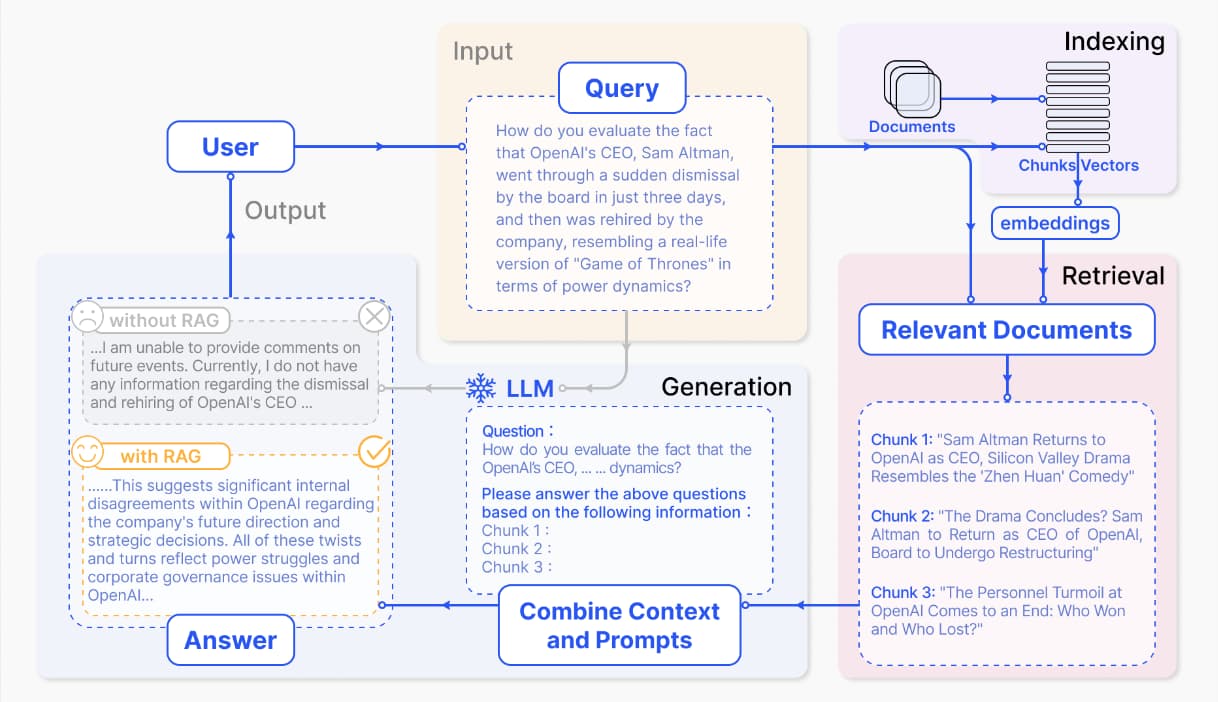
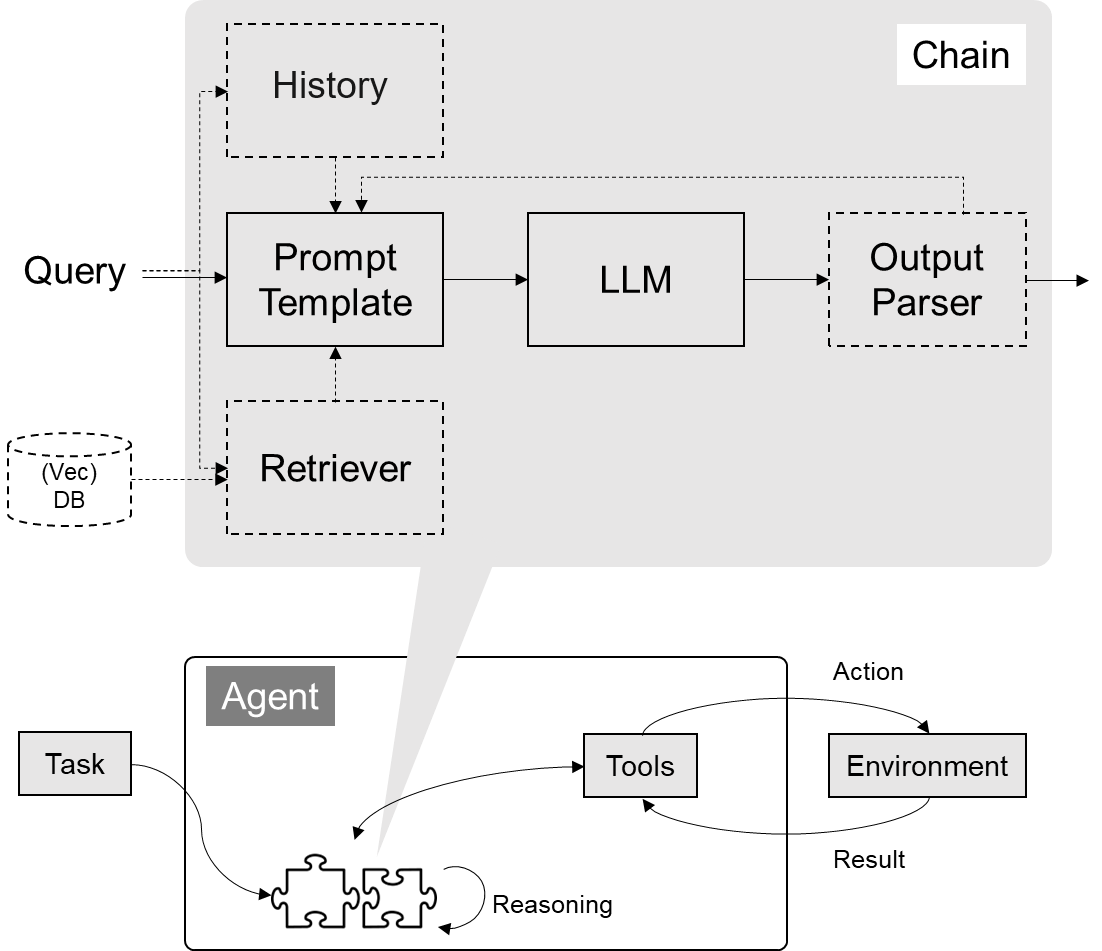
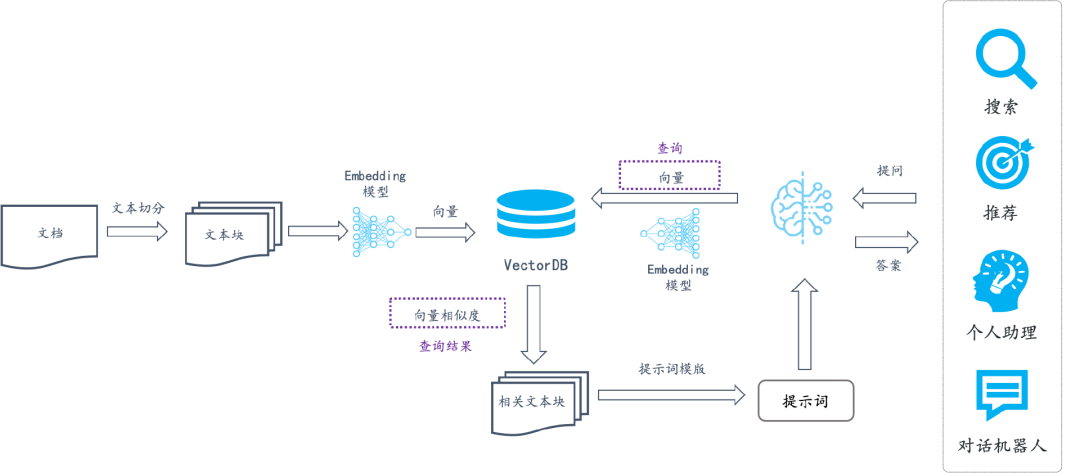
环境配置
internlm2 模型部署
创建虚拟环境
conda create -n deepseek_rag python=3.10 -y
conda activate deepseek_rag并在环境中安装运行 demo 所需要的依赖
# 升级pip
python -m pip install --upgrade pip
pip install modelscope==1.9.5
pip install transformers==4.35.2
pip install streamlit==1.24.0
pip install sentencepiece==0.1.99
pip install accelerate==0.24.1模型下载
使用 modelscope 中的 snapshot_download 函数下载模型,第一个参数为模型名称,参数 cache_dir 为模型的下载路径。
在 /root 路径下新建目录 data,在目录下新建 download.py 文件并在其中输入以下内容,粘贴代码后记得保存文件,如下图所示。并运行 python /root/data/download.py 执行下载,模型大小为 14 GB,下载模型大概需要 10~20 分钟
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('Shanghai_AI_Laboratory/internlm2-chat-1_8b', cache_dir='/workspace/deepseek_rag/model')同时,下载开源词向量模型 Sentence Transformer,使用 huggingface 官方提供的 huggingface-cli 命令行工具。安装依赖:
pip install -U huggingface_hub然后在和 /root/data 目录下新建python文件 download_hf.py,填入以下代码:
resume-download:断点续下
local-dir:本地存储路径。(linux环境下需要填写绝对路径)
import os
# 下载模型
os.system('huggingface-cli download --resume-download sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 --local-dir /root/data/model/sentence-transformer')但是,使用 huggingface 下载可能速度较慢,我们可以使用 huggingface 镜像下载。与使用hugginge face下载相同,只需要填入镜像地址即可。
将 download_hf.py 中的代码修改为以下代码:
import os
# 设置环境变量
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
# 下载模型
os.system('huggingface-cli download --resume-download sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 --local-dir /root/data/model/sentence-transformer')然后,在 /root/data 目录下执行该脚本即可自动开始下载:
python download_hf.pyLangChain相关配置
pip install langchain==0.0.292
pip install gradio==4.4.0
pip install chromadb==0.4.15
pip install sentence-transformers==2.2.2
pip install unstructured==0.10.30
pip install markdown==3.3.7下载 NLTK 相关资源
用以下命令下载 nltk 资源并解压到服务器上:
cd /root
git clone https://gitee.com/yzy0612/nltk_data.git --branch gh-pages
cd nltk_data
mv packages/* ./
cd tokenizers
unzip punkt.zip
cd ../taggers
unzip averaged_perceptron_tagger.zip知识库搭建
数据收集
选择由上海人工智能实验室开源的一系列大模型工具开源仓库作为语料库来源,包括:
OpenCompass:面向大模型评测的一站式平台
IMDeploy:涵盖了 LLM 任务的全套轻量化、部署和服务解决方案的高效推理工具箱
XTuner:轻量级微调大语言模型的工具库
InternLM-XComposer:浦语·灵笔,基于书生·浦语大语言模型研发的视觉-语言大模型
Lagent:一个轻量级、开源的基于大语言模型的智能体(agent)框架
InternLM:一个开源的轻量级训练框架,旨在支持大模型训练而无需大量的依赖
# 进入到数据库盘
cd /root/data
# clone 上述开源仓库
git clone https://gitee.com/open-compass/opencompass.git
git clone https://gitee.com/InternLM/lmdeploy.git
git clone https://gitee.com/InternLM/xtuner.git
git clone https://gitee.com/InternLM/InternLM-XComposer.git
git clone https://gitee.com/InternLM/lagent.git
git clone https://gitee.com/InternLM/InternLM.git选用上述仓库中所有的 markdown、txt 文件作为示例语料库。首先将上述仓库中所有满足条件的文件路径找出来,我们定义一个函数,该函数将递归指定文件夹路径,返回其中所有满足条件(即后缀名为 .md 或者 .txt 的文件)的文件路径:
import os
def get_files(dir_path):
# args:dir_path,目标文件夹路径
file_list = []
for filepath, dirnames, filenames in os.walk(dir_path):
# os.walk 函数将递归遍历指定文件夹
for filename in filenames:
# 通过后缀名判断文件类型是否满足要求
if filename.endswith(".md"):
# 如果满足要求,将其绝对路径加入到结果列表
file_list.append(os.path.join(filepath, filename))
elif filename.endswith(".txt"):
file_list.append(os.path.join(filepath, filename))
return file_list加载数据
得到所有目标文件路径之后,使用 LangChain 提供的 FileLoader 对象来加载目标文件,得到由目标文件解析出的纯文本内容。由于不同类型的文件需要对应不同的 FileLoader,判断目标文件类型,并针对性调用对应类型的 FileLoader,同时,调用 FileLoader 对象的 load 方法来得到加载之后的纯文本对象:
from tqdm import tqdm
from langchain.document_loaders import UnstructuredFileLoader
from langchain.document_loaders import UnstructuredMarkdownLoader
def get_text(dir_path):
# args:dir_path,目标文件夹路径
# 首先调用上文定义的函数得到目标文件路径列表
file_lst = get_files(dir_path)
# docs 存放加载之后的纯文本对象
docs = []
# 遍历所有目标文件
for one_file in tqdm(file_lst):
file_type = one_file.split('.')[-1]
if file_type == 'md':
loader = UnstructuredMarkdownLoader(one_file)
elif file_type == 'txt':
loader = UnstructuredFileLoader(one_file)
else:
# 如果是不符合条件的文件,直接跳过
continue
docs.extend(loader.load())
return docs构建向量数据库
得到该列表之后,我们就可以将它引入到 LangChain 框架中构建向量数据库。由纯文本对象构建向量数据库,我们需要先对文本进行分块,接着对文本块进行向量化。
LangChain 提供了多种文本分块工具,此处我们使用字符串递归分割器,并选择分块大小为 500,块重叠长度为 150(由于篇幅限制,此处没有展示切割效果,学习者可以自行尝试一下,想要深入学习 LangChain 文本分块可以参考教程 《LangChain - Chat With Your Data》:
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, chunk_overlap=150)
split_docs = text_splitter.split_documents(docs)接着我们选用开源词向量模型 Sentence Transformer 来进行文本向量化。LangChain 提供了直接引入 HuggingFace 开源社区中的模型进行向量化的接口:
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(model_name="/root/data/model/sentence-transformer")同时,考虑到 Chroma 是目前最常用的入门数据库,我们选择 Chroma 作为向量数据库,基于上文分块后的文档以及加载的开源向量化模型,将语料加载到指定路径下的向量数据库:
from langchain.vectorstores import Chroma
# 定义持久化路径
persist_directory = 'data_base/vector_db/chroma'
# 加载数据库
vectordb = Chroma.from_documents(
documents=split_docs,
embedding=embeddings,
persist_directory=persist_directory # 允许我们将persist_directory目录保存到磁盘上
)
# 将加载的向量数据库持久化到磁盘上
vectordb.persist()整体脚本
将上述代码整合在一起为知识库搭建的脚本:
# 首先导入所需第三方库
from langchain.document_loaders import UnstructuredFileLoader
from langchain.document_loaders import UnstructuredMarkdownLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from tqdm import tqdm
import os
# 获取文件路径函数
def get_files(dir_path):
# args:dir_path,目标文件夹路径
file_list = []
for filepath, dirnames, filenames in os.walk(dir_path):
# os.walk 函数将递归遍历指定文件夹
for filename in filenames:
# 通过后缀名判断文件类型是否满足要求
if filename.endswith(".md"):
# 如果满足要求,将其绝对路径加入到结果列表
file_list.append(os.path.join(filepath, filename))
elif filename.endswith(".txt"):
file_list.append(os.path.join(filepath, filename))
return file_list
# 加载文件函数
def get_text(dir_path):
# args:dir_path,目标文件夹路径
# 首先调用上文定义的函数得到目标文件路径列表
file_lst = get_files(dir_path)
# docs 存放加载之后的纯文本对象
docs = []
# 遍历所有目标文件
for one_file in tqdm(file_lst):
file_type = one_file.split('.')[-1]
if file_type == 'md':
loader = UnstructuredMarkdownLoader(one_file)
elif file_type == 'txt':
loader = UnstructuredFileLoader(one_file)
else:
# 如果是不符合条件的文件,直接跳过
continue
docs.extend(loader.load())
return docs
# 目标文件夹
tar_dir = [
"/workspace/shusheng/InternLM",
"/workspace/shusheng/InternLM-XComposer",
"/workspace/shusheng/lagent",
"/workspace/shusheng/lmdeploy",
"/workspace/shusheng/opencompass",
"/workspace/shusheng/xtuner"
]
# 加载目标文件
docs = []
for dir_path in tar_dir:
docs.extend(get_text(dir_path))
# 对文本进行分块
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, chunk_overlap=150)
split_docs = text_splitter.split_documents(docs)
# 加载开源词向量模型
embeddings = HuggingFaceEmbeddings(model_name="/workspace/deepseek_rag/model/sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2")
# 构建向量数据库
# 定义持久化路径
persist_directory = '/workspace/deepseek_rag/data_base/vector_db/chroma'
# 加载数据库
vectordb = Chroma.from_documents(
documents=split_docs,
embedding=embeddings,
persist_directory=persist_directory # 允许我们将persist_directory目录保存到磁盘上
)
# 将加载的向量数据库持久化到磁盘上
vectordb.persist()internlm2接入LanggChain
从 LangChain.llms.base.LLM 类继承一个子类,并重写构造函数与 _call 函数。实现将 Deepseek 接入到 LangChain 框架中。完成 LangChain 的自定义 LLM 子类之后,可以以完全一致的方式调用 LangChain 的接口,而无需考虑底层模型调用的不一致。
from langchain.llms.base import LLM
from typing import Any, List, Optional
from langchain.callbacks.manager import CallbackManagerForLLMRun
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
class DeepSeek_LLM(LLM):
# 基于本地 DeepSeek 自定义 LLM 类
tokenizer : AutoTokenizer = None
model: AutoModelForCausalLM = None
def __init__(self, model_path :str):
# model_path: DeepSeek 模型路径
# 从本地初始化模型
super().__init__()
print("正在从本地加载模型...")
self.tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
self.model = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True).to(torch.bfloat16).cuda()
self.model = self.model.eval()
print("完成本地模型的加载")
def _call(self, prompt : str, stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any):
# 重写调用函数
system_prompt = """You are an AI assistant whose name is DeepSeek.
- DeepSeek is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless.
- DeepSeek can understand and communicate fluently in the language chosen by the user such as English and 中文.
"""
messages = [(system_prompt, '')]
response, history = self.model.generate(self.tokenizer, prompt , history=messages)
return response
@property
def _llm_type(self) -> str:
return "DeepSeek"在上述类定义中,我们分别重写了构造函数和 _call 函数:对于构造函数,我们在对象实例化的一开始加载本地部署的 InternLM 模型,从而避免每一次调用都需要重新加载模型带来的时间过长;_call 函数是 LLM 类的核心函数,LangChain 会调用该函数来调用 LLM,在该函数中,我们调用已实例化模型的 chat 方法,从而实现对模型的调用并返回调用结果。
构建检索问答链
加载向量数据库
通过 Chroma 以及上文定义的词向量模型来加载已构建的数据库:
from langchain.vectorstores import Chroma
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
import os
# 定义 Embeddings
embeddings = HuggingFaceEmbeddings(model_name="/root/data/model/sentence-transformer")
# 向量数据库持久化路径
persist_directory = 'data_base/vector_db/chroma'
# 加载数据库
vectordb = Chroma(
persist_directory=persist_directory,
embedding_function=embeddings
)实例化自定义 LLM 与 Prompt Template
实例化一个基于 InternLM 自定义的 LLM 对象:
from LLM import InternLM_LLM
llm = InternLM_LLM(model_path = "/root/data/model/Shanghai_AI_Laboratory/internlm-chat-7b")
llm.predict("你是谁")构建检索问答链,还需要构建一个 Prompt Template,该 Template 其实基于一个带变量的字符串,在检索之后,LangChain 会将检索到的相关文档片段填入到 Template 的变量中,从而实现带知识的 Prompt 构建。我们可以基于 LangChain 的 Template 基类来实例化这样一个 Template 对象:
from langchain.prompts import PromptTemplate
# 我们所构造的 Prompt 模板
template = """使用以下上下文来回答用户的问题。如果你不知道答案,就说你不知道。总是使用中文回答。
问题: {question}
可参考的上下文:
···
{context}
···
如果给定的上下文无法让你做出回答,请回答你不知道。
有用的回答:"""
# 调用 LangChain 的方法来实例化一个 Template 对象,该对象包含了 context 和 question 两个变量,在实际调用时,这两个变量会被检索到的文档片段和用户提问填充
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context","question"],template=template)4.3 构建检索问答链
最后,可以调用 LangChain 提供的检索问答链构造函数,基于我们的自定义 LLM、Prompt Template 和向量知识库来构建一个基于 InternLM 的检索问答链:
from langchain.chains import RetrievalQA
qa_chain = RetrievalQA.from_chain_type(llm,retriever=vectordb.as_retriever(),return_source_documents=True,chain_type_kwargs={"prompt":QA_CHAIN_PROMPT})得到的 qa_chain 对象即可以实现我们的核心功能,即基于 InternLM 模型的专业知识库助手。我们可以对比该检索问答链和纯 LLM 的问答效果:
# 检索问答链回答效果
question = "什么是InternLM"
result = qa_chain({"query": question})
print("检索问答链回答 question 的结果:")
print(result["result"])
# 仅 LLM 回答效果
result_2 = llm(question)
print("大模型回答 question 的结果:")
print(result_2)