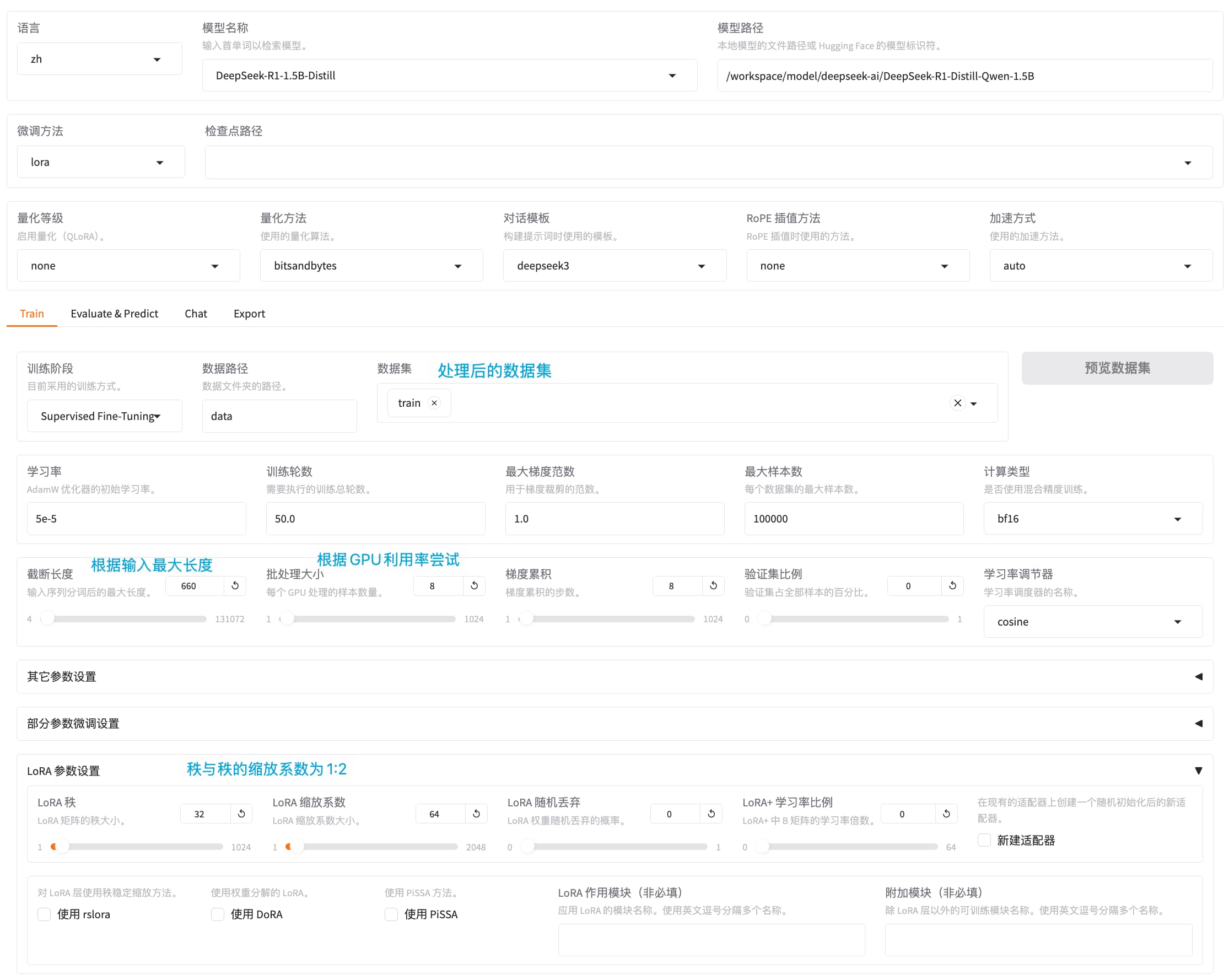
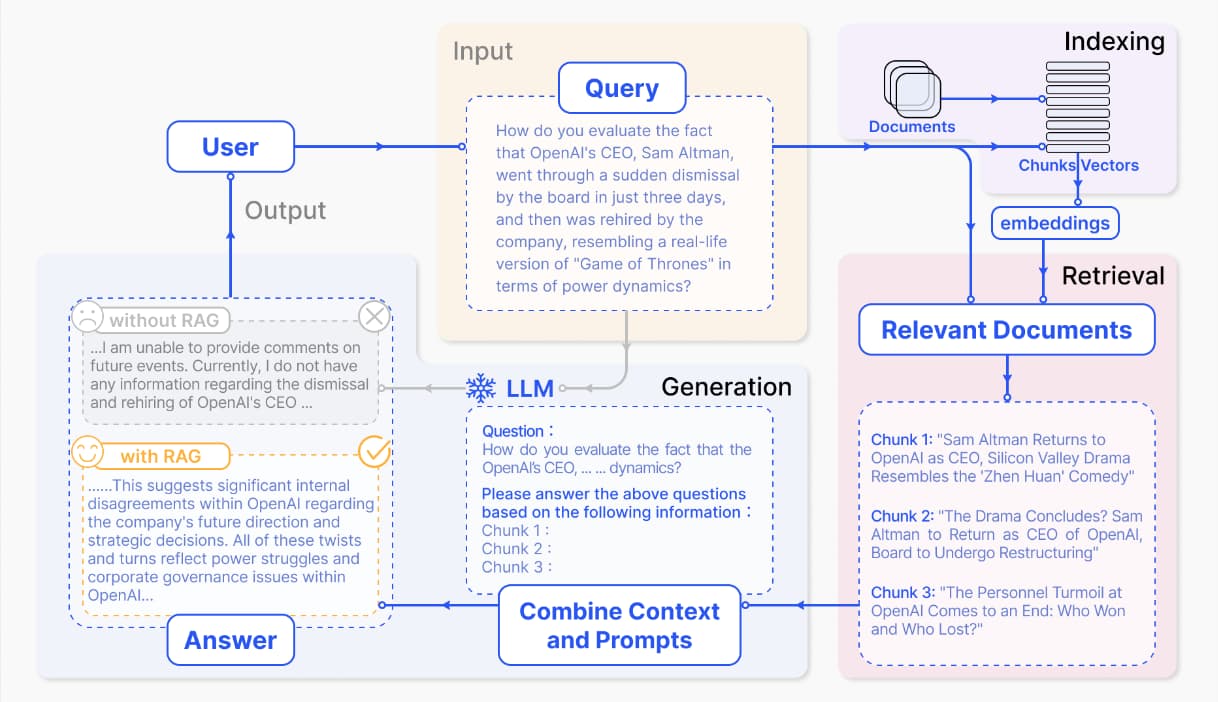
简介
LLama-Factory整合主流训练微调技术,适配LLaMA、Qwen、ChatGpt等主流开源模型,包含预训练(pt),指令微调(sft),基于人工反馈的对齐(rlhf)等全链路,对于不同下游的使用场景和垂直领域进行微调训练的开源框架。
安装
环境校验
# CUDA和GPU环境
nvidia-smi
(base) root@VM-0-10-ubuntu:/workspace# nvidia-smi
Thu Jan 9 14:33:15 2025
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.105.17 Driver Version: 525.105.17 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 On | 00000000:00:09.0 Off | 0 |
| N/A 68C P0 61W / 70W | 14516MiB / 15360MiB | 100% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
+-----------------------------------------------------------------------------+
# Pytorch环境校验
>>> import torch
>>> print(torch.__version__)
2.5.1+cu124
下载并安装
git clone https://github.com/hiyouga/LLaMA-Factory.git # 下载
conda create -n llama_factory python=3.10 # 新建一个LLaMA-Factory 使用的python环境(可选)
conda activate llama_factory
cd LLaMA-Factory
pip install -e '.[torch,metrics]'上述的安装命令完成了如下几件事
新建一个LLaMA-Factory 使用的python环境(可选)
安装LLaMA-Factory 所需要的第三方基础库(requirements.txt包含的库)
安装评估指标所需要的库,包含nltk, jieba, rouge-chinese
安装LLaMA-Factory本身,然后在系统中生成一个命令 llamafactory-cli
# 环境正确性校验
>>> import torch
>>> print(torch.__version__)
2.5.1+cu124
>>> torch.cuda.current_device()
name(0)0
>>> torch.cuda.get_device_name(0)
'Tesla T4'
# 基础安装做一下校验,输入以下命令获取训练相关的参数指导, 否则说明库还没有安装成功
(base) root@VM-0-10-ubuntu:/workspace# llamafactory-cli train -h
usage: llamafactory-cli [-h] [--ray_run_name RAY_RUN_NAME] [--ray_num_workers RAY_NUM_WORKERS]
[--resources_per_worker RESOURCES_PER_WORKER]
[--placement_strategy {SPREAD,PACK,STRICT_SPREAD,STRICT_PACK}]
options:
-h, --help show this help message and exit
--ray_run_name RAY_RUN_NAME, --ray-run-name RAY_RUN_NAME
The training results will be saved at `saves/ray_run_name`. (default: None)
--ray_num_workers RAY_NUM_WORKERS, --ray-num-workers RAY_NUM_WORKERS
The number of workers for Ray training. Default is 1 worker. (default: 1)
--resources_per_worker RESOURCES_PER_WORKER, --resources-per-worker RESOURCES_PER_WORKER
The resources per worker for Ray training. Default is to use 1 GPU per worker. (default: {'GPU': 1})
--placement_strategy {SPREAD,PACK,STRICT_SPREAD,STRICT_PACK}, --placement-strategy {SPREAD,PACK,STRICT_SPREAD,STRICT_PACK}
The placement strategy for Ray training. Default is PACK. (default: PACK)
(base) root@VM-0-10-ubuntu:/workspace# 模型下载
使用手动下载,然后后续使用时使用绝对路径来控制使用哪个模型。
以Meta-Llama-3-8B-Instruct为例,通过huggingface 下载
git clone https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instructmodelscope 下载
git clone https://www.modelscope.cn/LLM-Research/Meta-Llama-3-8B-Instruct.git或者
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('LLM-Research/Meta-Llama-3-8B-Instruct')llamafactory-cli命令及参数
直接调用原始模型
llamafactory-cli webchat \
--model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct \
--template llama3也可以使用配置文件
# llama3.yaml
model_name_or_path: /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct
template: llama3
llamafactory-cli webchat examples/inference/llama3.yaml自定义数据集构建
LLama Factory数据集格式在不同阶段要求是不同的,目前支持 alpaca 和sharegpt两种数据格式,以alpaca为例,整个数据集是一个json对象的list,具体数据格式为
[
{
"instruction": "用户指令(必填)",
"input": "用户输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]训练的数据最好也转换成这种格式,然后在 data/dataset_info.json中进行注册(如果不做字段名称转换,则需要在注册的时候在 columns字段中做两个数据的映射配置)
系统自带的identity.json数据集
在data/dataset_info.json 注册为identity
{
"instruction": "Who are you?",
"input": "",
"output": "Hello! I am {{name}}, an AI assistant developed by {{author}}. How can I assist you today?"
}
# 修改名称和作者
sed -i 's/{{name}}/PonyBot/g' data/identity.json
sed -i 's/{{author}}/LLaMA Factory/g' data/identity.json 文案生成数据集
训练目标是输入content (也就是prompt), 输出 summary (对应response)
{
"content": "类型#裤*版型#宽松*风格#性感*图案#线条*裤型#阔腿裤",
"summary": "宽松的阔腿裤这两年真的吸粉不少,明星时尚达人的心头爱。毕竟好穿时尚,谁都能穿出腿长2米的效果宽松的裤腿,当然是遮肉小能手啊。上身随性自然不拘束,面料亲肤舒适贴身体验感棒棒哒。系带部分增加设计看点,还让单品的设计感更强。腿部线条若隐若现的,性感撩人。颜色敲温柔的,与裤子本身所呈现的风格有点反差萌。"
}该自定义数据集放到系统中使用,则需要进行如下两步操作
复制该数据集到 data目录下
修改 data/dataset_info.json 新加内容完成注册
自定义数据集的名称,后续训练的时候就使用这个名称来找到该数据集
指定了数据集具体文件位置
定义了原数据集的输入输出和我们所需要的格式之间的映射关系
基于LoRA的sft指令微调
准备好数据集之后,可以开始准备训练,训练的目标就是让原来的LLaMA3模型能够学会自定义的“你是谁”,同时学会提供的数据集中文案的一些生成。
训练过程中,系统会按照logging_steps的参数设置,定时输出训练日志,包含当前loss,训练进度等
73%|██████████████████████████████████████████████████████████████▋ | 175/240 [1:56:55<40:56, 37.79s/it][INFO|2025-01-09 14:54:13] llamafactory.train.callbacks:157 >> {'loss': 1.2825, 'learning_rate': 8.5164e-06, 'epoch': 7.14}
{'loss': 1.2825, 'grad_norm': 1.5290024280548096, 'learning_rate': 8.51635462249828e-06, 'epoch': 7.14}
75%|████████████████████████████████████████████████████████████████▌ | 180/240 [2:00:37<42:58, 42.97s/it][INFO|2025-01-09 14:57:55] llamafactory.train.callbacks:157 >> {'loss': 0.9211, 'learning_rate': 7.3223e-06, 'epoch': 7.35}
{'loss': 0.9211, 'grad_norm': 1.0087417364120483, 'learning_rate': 7.3223304703363135e-06, 'epoch': 7.35}
77%|██████████████████████████████████████████████████████████████████▎ | 185/240 [2:03:43<32:35, 35.56s/it][INFO|2025-01-09 15:01:01] llamafactory.train.callbacks:157 >> {'loss': 1.1355, 'learning_rate': 6.2040e-06, 'epoch': 7.55}
{'loss': 1.1355, 'grad_norm': 1.12874436378479, 'learning_rate': 6.204004813025568e-06, 'epoch': 7.55} 训练完后就可以在设置的output_dir下看到如下内容,主要包含3部分
adapter开头的就是 LoRA保存的结果了,后续用于模型推理融合
training_loss 和trainer_log等记录了训练的过程指标
其他是训练当时各种参数的备份
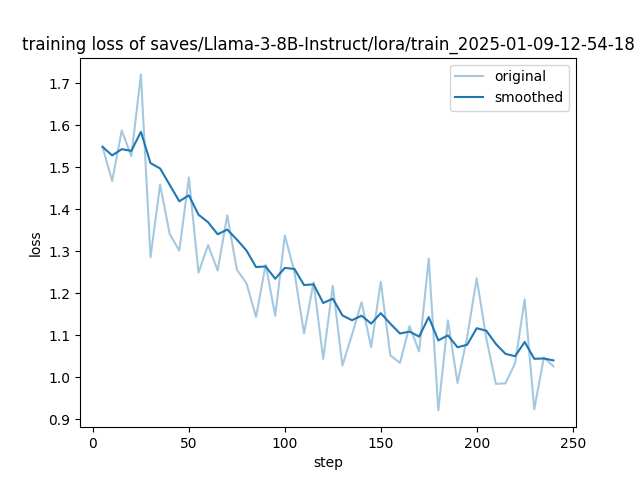
命令行训练
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train \
--stage sft \
--do_train \
--model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct \
--dataset alpaca_gpt4_zh,identity,adgen_local \
--dataset_dir ./data \
--template llama3 \
--finetuning_type lora \
--output_dir ./saves/LLaMA3-8B/lora/sft \
--overwrite_cache \
--overwrite_output_dir \
--cutoff_len 1024 \
--preprocessing_num_workers 16 \
--per_device_train_batch_size 2 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--logging_steps 50 \
--warmup_steps 20 \
--save_steps 100 \
--eval_steps 50 \
--evaluation_strategy steps \
--load_best_model_at_end \
--learning_rate 5e-5 \
--num_train_epochs 5.0 \
--max_samples 1000 \
--val_size 0.1 \
--plot_loss \
--fp16动态合并LoRA的推理
CUDA_VISIBLE_DEVICES=0 llamafactory-cli webchat \
--model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct \
--adapter_name_or_path ./saves/LLaMA3-8B/lora/sft \
--template llama3 \
--finetuning_type lora基于LoRA的训练结束后,通过finetuning_type参数告诉系统,使用了LoRA训练,然后将LoRA的模型位置通过 adapter_name_or_path参数。
CUDA_VISIBLE_DEVICES=0 llamafactory-cli chat \
--model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct \
--adapter_name_or_path ./saves/LLaMA3-8B/lora/sft \
--template llama3 \
--finetuning_type loraLoRA模型合并导出
把训练的LoRA和原始的大模型进行融合,输出一个完整的模型文件的话,可以使用如下命令。合并后的模型可以自由地像使用原始的模型一样应用到其他下游环节,当然也可以递归地继续用于训练。
CUDA_VISIBLE_DEVICES=0 llamafactory-cli export \
--model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct \
--adapter_name_or_path ./saves/LLaMA3-8B/lora/sft \
--template llama3 \
--finetuning_type lora \
--export_dir megred-model-path \
--export_size 2 \
--export_device cpu \
--export_legacy_format False通过配置文件合并merge_llama3_lora_sft.yaml
### Note: DO NOT use quantized model or quantization_bit when merging loraadapters
### model
model_name_or_path: /root/autodl-tmp/models/Llama3-8B-Chinese-Chat/
adapter_name_or_path: /root/code/LLaMA-Factory/saves/LLaMA3-8B-ChineseChat/lora/train_2024-05-25-20-27-47
template: llama3
finetuning_type: lora
### export
export_dir: /root/autodl-tmp/models/LLaMA3-8B-Chinese-Chat-merged
export_size: 4
export_device: cuda
export_legacy_format: falsellamafactory-cli export cust/merge_llama3_lora_sft.yaml批量预测和训练效果评估
当然上文中的人工交互测试,会偏感性,那有没有办法批量地预测一批数据,然后使用自动化的bleu和 rouge等常用的文本生成指标来做评估。指标计算会使用如下3个库
pip install jieba
pip install rouge-chinese
pip install nltk本脚本参数改编自 https://A-Factory/blob/main/examples/train_lora/llama3_lora_predict.yaml
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train \
--stage sft \
--do_predict \
--model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct \
--adapter_name_or_path ./saves/LLaMA3-8B/lora/sft \
--eval_dataset alpaca_gpt4_zh,identity,adgen_local \
--dataset_dir ./data \
--template llama3 \
--finetuning_type lora \
--output_dir ./saves/LLaMA3-8B/lora/predict \
--overwrite_cache \
--overwrite_output_dir \
--cutoff_len 1024 \
--preprocessing_num_workers 16 \
--per_device_eval_batch_size 1 \
--max_samples 20 \
--predict_with_generate与训练脚本主要的参数区别如下两个
predict_bleu-4 : BLEU-4 得分,19.43。
predict_model_preparation_time : 模型准备时间,0.0076 秒。
predict_rouge-1 : ROUGE-1 得分,41.59。
predict_rouge-2 : ROUGE-2 得分,19.29。
predict_rouge-l : ROUGE-L 得分,30.12。
predict_runtime : 总运行时间,2085.6627 秒。
predict_samples_per_second : 每秒处理样本数,0.192。
predict_steps_per_second : 每秒处理步骤数,0.096。generated_predictions.jsonl 文件 输出了要预测的数据集的原始label和模型predict的结果
predict_results.json给出了原始label和模型predict的结果,用自动计算的指标数据
API Server的启动与调用
API 实现的标准是参考了OpenAI的相关接口协议,将模型的能力形成一个可访问的网络接口,通过API 来调用,接入到langchian或者其他下游业务中。
CUDA_VISIBLE_DEVICES=0 API_PORT=8000 llamafactory-cli api \
--model_name_or_path megred-model-path \
--template llama3 \
--infer_backend vllm \
--vllm_enforce_eagerimport os
from openai import OpenAI
from transformers.utils.versions import require_version
require_version("openai>=1.5.0", "To fix: pip install openai>=1.5.0")
if __name__ == '__main__':
# change to your custom port
port = 8000
client = OpenAI(
api_key="0",
base_url="http://localhost:{}/v1".format(os.environ.get("API_PORT", 8000)),
)
messages = []
messages.append({"role": "user", "content": "hello, where is USA"})
result = client.chat.completions.create(messages=messages, model="test")
print(result.choices[0].message)