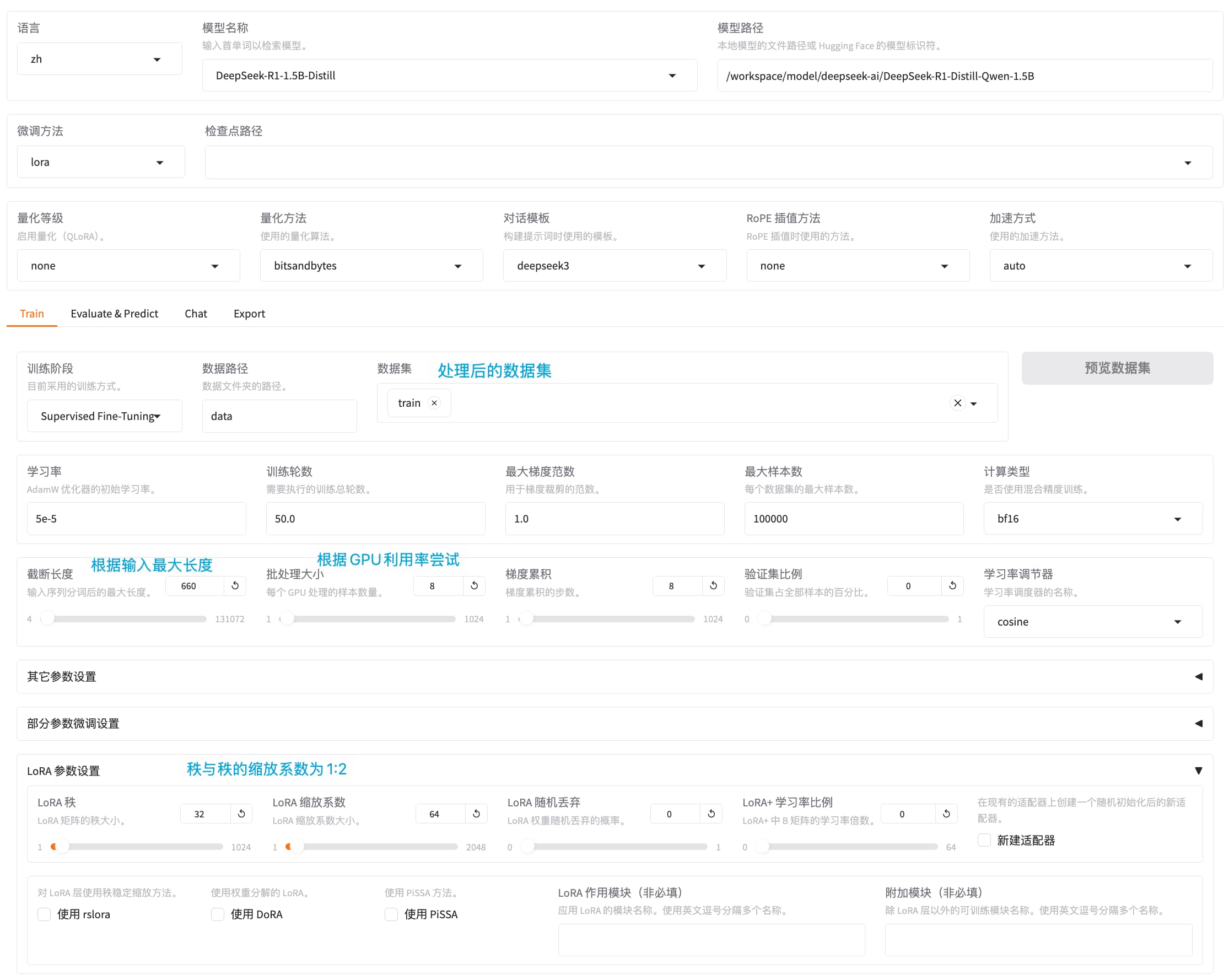
Ollama
安装Ollama
使用Ollama
启动Ollama
ollama serve拉取模型
ollama pull llama3移除模型
ollama rm llama3复制模型
ollama cp llama3.2 my-model查看模型信息
ollama show llama3
查看系统中已下载的模型
ollama list查看当前使用的模型
ollama ps停止正在运行的模型
ollama stop llama3加载模型
ollama run llama3
llama % ollama run llama3
pulling manifest
pulling 6a0746a1ec1a... 100% ▕███████████████▏ 4.7 GB
pulling 4fa551d4f938... 100% ▕███████████████▏ 12 KB
pulling 8ab4849b038c... 100% ▕███████████████▏ 254 B
pulling 577073ffcc6c... 100% ▕███████████████▏ 110 B
pulling 3f8eb4da87fa... 100% ▕███████████████▏ 485 B
verifying sha256 digest
writing manifest
success
>>> Send a message (/? for help)多轮输入:For multiline input, you can wrap text with
"""
>>> """Hello,
... world!
... """
I'm a basic program that prints the famous "Hello, world!" message to the console.多模态
ollama run llava "What's in this image? /Users/jmorgan/Desktop/smile.png"
The image features a yellow smiley face, which is likely the central focus of the picture.将提示词作为参数使用
$ ollama run llama3 "Summarize this file: $(cat README.md)"
Ollama is a lightweight, extensible framework for building and running language models on the local machine. It provides a simple API for creating, running, and managing models, as well as a library of pre-built models that can be easily used in a variety of applications.llama交互
命令行
>>> 你好,请使用中文介绍自己
😊 你好!我是一个人工智能,是由 MetaAI 开发的一款语言模型。我的主要功能是理
解自然语言,并以与人类类似的方式回应。我可以和用户进行对话,回答问题,并且
能够学习新知识。
在训练数据中,我学到了大量的中文文本,这让我能够处理中文问答任务。但是我不
是专业的翻译工具,也不是机器翻译系统。我更像是一个聊天的朋友,可以与您进行
温暖的交流。
我可以聊关于任何话题,从科技到娱乐,从生活到文化等等。我的目标是帮助用户解
决问题、提高沟通效率,并且提供有趣的对话体验。
如果您需要帮助或只是想聊天,请随时和我聊天! 😊Api
from openai import OpenAI
client = OpenAI(base_url="http://localhost:11434/v1/",api_key="ollama")
chatbot = client.chat.completions.create(
messages=[{"role":"user","content":"你好,请介绍一下自己"}],model="llama3"
)
print(chatbot.choices[0])
“”“
Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='😊 Ni Hao! (That\'s "hello" in Mandarin, by the way!)\n\nI\'m LLaMA, a large language model trained by a team of researcher at Meta AI. My main function is to understand and generate human-like text based on the input I receive.\n\nI was created through a process called transformer-based machine learning, which allows me to learn from large datasets of text and improve my accuracy over time. My training data includes an enormous amount of text from various sources such as books, articles, and conversations.\n\nAs a conversational AI, I can:\n\n1. Answer questions: I can process natural language queries and provide relevant answers.\n2. Generate text: I can create new text based on the input I receive, including stories, dialogues, or even entire essays.\n3. Summarize content: I can summarize long pieces of text into shorter, more digestible versions.\n4. Translate languages: I have been trained on a large corpus of texts in multiple languages, so I can translate simple phrases and sentences from one language to another.\n\nI\'m still learning and improving my abilities every day. My training data is constantly being updated, which allows me to keep up with the latest trends, slang, and knowledge in various domains.\n\nSo, what do you want to talk about? Ask me a question, or give me a prompt, and I\'ll respond according to my training! 💬', refusal=None, role='assistant', audio=None, function_call=None, tool_calls=None))
”“”多伦对话
from openai import OpenAI
def run_chat_session():
# 初始化客户端
client = OpenAI(base_url="http://localhost:11434/v1/",api_key="ollama")
# 初始化对话信息
chat_history = []
# 启动多伦对话
while True:
# 获取用户输入
user_input = input("用户:")
if user_input.lower() == "exit":
print("bye, next to neet you !")
break
# 更新历史对话信息(用户的输入)
chat_history.append({"role":"user","content":user_input})
# 调用模型回答
try:
chat_completion = client.chat.completions.create(messages=chat_history,model="llama3")
# 获取最新回答
model_res = chat_completion.choices[0].message.content
print(model_res)
chat_history.append({"role":"user","content":model_res})
except Exception as e:
print("sthing is error")
break
if __name__ == '__main__':
run_chat_session()ModelScope | Hugging Face
下载模型Llama
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('LLM-Research/Meta-Llama-3-8B-Instruct',cache_dir="/Volumes/Date/huggingface/model/llama")使用transformers调用模型
from transformers import AutoModelForCausalLM,AutoTokenizer
device = "cpu"
model_dir = "/Volumes/Date/huggingface/model/llama/LLM-Research/Meta-Llama-3-8B-Instruct"
model = AutoModelForCausalLM.from_pretrained(model_dir,torch_dtype='auto')
tokenizer=AutoTokenizer.from_pretrained(model_dir)
#加载与模型相匹配的分词器。分词器用于将文本转换成模型能够理解和处
prompt="你好,请介绍下你自己。"
messages=[{'role':'system','content':'You are a helpful assistant system'},
{'role': 'user','content': prompt}]
# 使用分词器的 apply_chat_template 方法将上面定义的消,息列表转护# tokenize=False 表示此时不进行令牌化,add_generation_promp
text =tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
#将处理后的文本令牌化并转换为模型输入张量,然后将这些张量移至之前
model_inputs=tokenizer([text],return_tensors="pt").to('cpu')
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
# 对输出进行解码
response=tokenizer.batch_decode(generated_ids, skip_special_tokens=True)