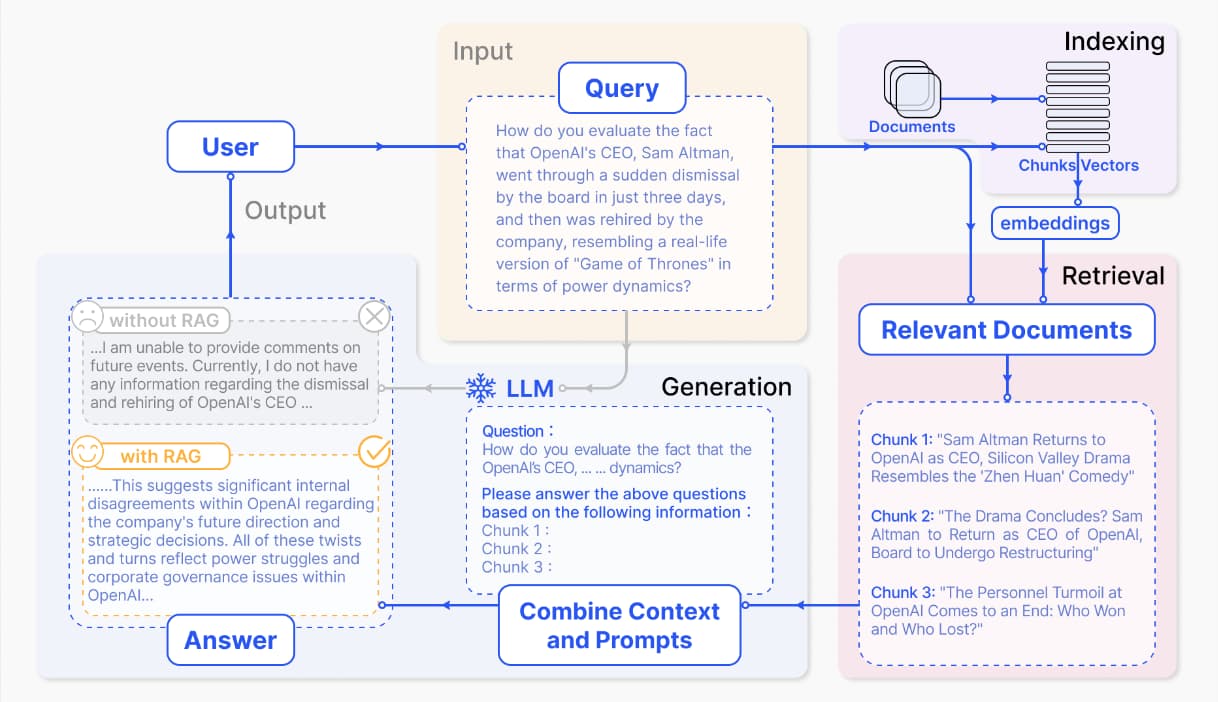
GPT-2 是一种基于 Transformer 的生成模型,专注于生成连贯的文本。在 Hugging Face 的Transformers 库中,GPT-2 已经被应用于多种中文文本生成任务,如古诗词、歌词和对联生成等。
GPT-2模型
from transformers import BertTokenizer,GPT2LMHeadModel,TextGenerationPipeline
tokenizer = BertTokenizer.from_pretrained(r"/Volumes/Date/huggingface/model/gpt2-chinese/models--uer--gpt2-chinese-cluecorpussmall/snapshots/c2c0249d8a2731f269414cc3b22dff021f8e07a3")
model = GPT2LMHeadModel.from_pretrained(r"/Volumes/Date/huggingface/model/gpt2-chinese/models--uer--gpt2-chinese-cluecorpussmall/snapshots/c2c0249d8a2731f269414cc3b22dff021f8e07a3")
print(model)
“”“
GPT2LMHeadModel(
(transformer): GPT2Model(
(wte): Embedding(21128, 768)
(wpe): Embedding(1024, 768)
(drop): Dropout(p=0.1, inplace=False)
(h): ModuleList(
(0-11): 12 x GPT2Block(
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): GPT2SdpaAttention(
(c_attn): Conv1D(nf=2304, nx=768)
(c_proj): Conv1D(nf=768, nx=768)
(attn_dropout): Dropout(p=0.1, inplace=False)
(resid_dropout): Dropout(p=0.1, inplace=False)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): GPT2MLP(
(c_fc): Conv1D(nf=3072, nx=768)
(c_proj): Conv1D(nf=768, nx=3072)
(act): NewGELUActivation()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(lm_head): Linear(in_features=768, out_features=21128, bias=False)
)
”“”模型输入数据信息
输入文本:输入文本需要先通过分词器(如
BertTokenizer)进行编码,转换为模型可以理解的格式。具体来说,输入文本会被分割成一个个token(词汇或字符),并映射到模型的词汇表中对应的ID。输入张量
input_ids:这是一个二维张量,形状为
[batch_size, sequence_length],其中batch_size是批次大小,`sequence_length` 是序列长度。每个元素是词汇表中的token ID。attention_mask(可选):用于指示哪些位置是有效的token(值为1),哪些位置是填充的(值为0)。形状为
[batch_size, sequence_length]。position_ids(可选):用于指示每个token在序列中的位置。形状为
[batch_size, sequence_length]。token_type_ids(可选):用于区分不同类型的token(例如,在句子对任务中区分两个句子)。形状为
[batch_size, sequence_length]。
模型输出数据信息
输出张量
logits:这是模型生成的每个位置上所有可能token的概率分布。形状为
[batch_size, sequence_length, vocab_size],其中vocab_size是词汇表的大小(21128)。每个位置上的概率分布可以通过softmax函数转换为概率值。past_key_values(可选):用于加速推理过程中的自回归生成。包含之前计算的注意力键和值,可以在生成下一个token时复用。
模型结构
Embedding层
wte (word embeddings):将输入的token ID嵌入到768维的向量空间中。形状为
[vocab_size, hidden_size],其中hidden_size=768。wpe (position embeddings):将每个token的位置信息嵌入到768维的向量空间中。形状为
[max_position_embeddings, hidden_size],其中max_position_embeddings=1024。
Dropout层:在嵌入层之后应用一个dropout层,以防止过拟合。dropout概率为0.1。
Transformer层:包含12个
GPT2Block,每个块由以下部分组成:LayerNorm (ln_1):在多头自注意力机制之前应用层归一化。
Attention (attn):多头自注意力机制,用于捕捉输入序列中的依赖关系。包括三个子模块:
c_attn:线性变换,将输入映射到查询、键和值的组合空间。
c_proj:线性变换,将注意力结果映射回隐藏状态空间。
attn_dropout 和 resid_dropout:分别应用于注意力权重和残差连接的dropout层。
LayerNorm (ln_2):在前馈神经网络之前应用层归一化。
MLP (mlp):两层全连接网络,激活函数为
NewGELUActivation,并在最后一层应用dropout。
Final LayerNorm:在所有Transformer层之后应用最终的层归一化。
Language Model Head (lm_head):线性变换,将隐藏状态映射回词汇表大小的空间。形状为
[hidden_size, vocab_size],没有偏置项。
工作流程
1. 输入处理:输入文本通过分词器编码为 input_ids,并可能附加 attention_mask 和 position_ids。
2. 嵌入层:将 input_ids 和 position_ids 转换为嵌入向量,并应用dropout。
3. Transformer层:嵌入向量依次通过12个 GPT2Block,每个块内部进行多头自注意力计算和前馈神经网络变换。
4. 输出层:最终的隐藏状态通过 lm_head 线性变换,得到每个位置上所有可能token的概率分布。
5. 生成文本:使用生成策略(如贪心搜索、束搜索或采样)从概率分布中选择最合适的token,逐步生成新的文本。
GPT-2 中文模型推理调用
中文白话文生成
from transformers import BertTokenizer,GPT2LMHeadModel,TextGenerationPipeline
tokenizer = BertTokenizer.from_pretrained(r"/Volumes/Date/huggingface/model/gpt2-chinese/models--uer--gpt2-chinese-cluecorpussmall/snapshots/c2c0249d8a2731f269414cc3b22dff021f8e07a3")
model = GPT2LMHeadModel.from_pretrained(r"/Volumes/Date/huggingface/model/gpt2-chinese/models--uer--gpt2-chinese-cluecorpussmall/snapshots/c2c0249d8a2731f269414cc3b22dff021f8e07a3")
#device=0,device="coda" 指定当前的推理设备为第一块GPU;如果没有GPU环境,就去掉该参数
text_generator = TextGenerationPipeline(model,tokenizer)
#使用过text_generator生成文本
out = text_generator("这是很久之前的事情了,",max_length=100,do_sample=True)
print(out)
# do_sample是否进行随机采样,True:每次生成结果不通过。False:每次生成结果想通过
for i in range(3):
print(text_generator("这是很久之前的事情了,",max_length=100,do_sample=True))
for i in range(3):
print(text_generator("这是很久之前的事情了,",max_length=100,do_sample=False))BertTokenizer :用于将输入文本转换为模型可以处理的格式。这里我们使用预训练的uer/gpt2-chinese-lyric 模型的分词器。
GPT2LMHeadModel :GPT-2 模型的实现,专注于语言模型的生成任务。
TextGenerationPipeline :Hugging Face 提供的简化工具,用于快速生成文本。它结合了模型和分词器,简化了推理过程。
do_sample=True :启用随机采样,使得每次生成的文本可能不同,这有助于生成多样化的结果。
device=0 :指定使用第一个 GPU 进行计算。如果系统有多个 GPU,可以通过改变设备编号选择其他 GPU。
max_length=100 :设置生成文本的最大长度,以确保生成的文本不会超出指定的字符数。
[{'generated_text': '这是很久之前的事情了, 大 二 的 时 候 , 来 过 几 次 , 主 要 是 陪 女 友 去 过 一 次 。 因 为 没 有 什 么 时 间 。 第 一 次 看 见 这 家 店 , 是 小 学 的 时 候 老 去 。 里 面 满 满 的 都 是 阿 姨 , 还 有 老 师 。 那 次 是 和 女 友 去 了 , 所 以 老 师 就 送 我 们 一 张 纸 画 。 我'}]
[{'generated_text': '这是很久之前的事情了, 啊 ! 在 里 面 逛 街 , 饿 了 , 就 会 叫 外 卖 吃 , 一 般 都 是 半 小 时 就 送 到 了 ~ 一 般 没 什 么 特 别 的 , 除 了 牛 肉 饭 之 外 , 还 配 有 凉 拌 菜 和 凉 菜 。 送 来 的 速 度 很 快 , 里 面 的 卤 蛋 和 小 笼 都 很 好 吃 呢 ~ , 这 里 有 一 段 时'}]
[{'generated_text': '这是很久之前的事情了, 么 上 次 就 想 换 换 口 味 , 就 来 吃 了 。 本 来 就 是 冲 着 那 个 锅 来 的 , 哈 哈 ! 而 且 都 没 怎 么 吃 啊 ! 里 面 就 加 面 吧 , 当 然 啦 加 的 面 是 要 钱 的 , 加 的 就 是 面 条 。 本 来 想 加 个 青 菜 , 结 果 点 了 很 多 的 。 么 下 次 去 吃 。'}]
[{'generated_text': '这是很久之前的事情了, 前 段 时 间 才 知 道 呢 。 离 单 位 很 近 , 所 以 经 常 去 , 老 板 很 热 情 , 但 是 我 觉 得 没 什 么 事 的 时 候 就 会 去 小 店 , 也 很 快 乐 , 挺 好 的 , 就 是 价 格 贵 了 些 。 每 次 去 , 感 觉 都 不 太 好 , 人 气 好 像 也 不 是 很 旺 吧 。 记 得'}]
[{'generated_text': '这是很久之前的事情了, 前 几 天 和 朋 友 去 吃 了 一 次 , 感 觉 还 不 错 , 就 是 环 境 差 了 点 , 不 过 味 道 还 是 不 错 的 , 价 格 也 不 贵 , 很 适 合 朋 友 聚 会 , 情 侣 约 会 , 家 庭 聚 会 , 朋 友 聚 会 , 都 是 不 错 的 选 择 。'}]
[{'generated_text': '这是很久之前的事情了, 前 几 天 和 朋 友 去 吃 了 一 次 , 感 觉 还 不 错 , 就 是 环 境 差 了 点 , 不 过 味 道 还 是 不 错 的 , 价 格 也 不 贵 , 很 适 合 朋 友 聚 会 , 情 侣 约 会 , 家 庭 聚 会 , 朋 友 聚 会 , 都 是 不 错 的 选 择 。'}]
[{'generated_text': '这是很久之前的事情了, 前 几 天 和 朋 友 去 吃 了 一 次 , 感 觉 还 不 错 , 就 是 环 境 差 了 点 , 不 过 味 道 还 是 不 错 的 , 价 格 也 不 贵 , 很 适 合 朋 友 聚 会 , 情 侣 约 会 , 家 庭 聚 会 , 朋 友 聚 会 , 都 是 不 错 的 选 择 。'}]
中文歌词生成
#中文歌词生成模型
from transformers import GPT2LMHeadModel,BertTokenizer,TextGenerationPipeline
tokenizer = BertTokenizer.from_pretrained(r"/Volumes/Date/huggingface/model/gpt2-chinese/models--uer--gpt2-chinese-lyric/snapshots/4a42fd76daab07d9d7ff95c816160cfb7c21684f")
model = GPT2LMHeadModel.from_pretrained(r"/Volumes/Date/huggingface/model/gpt2-chinese/models--uer--gpt2-chinese-lyric/snapshots/4a42fd76daab07d9d7ff95c816160cfb7c21684f")
#创建模型推理对象
text_generator = TextGenerationPipeline(model,tokenizer)
out = text_generator("这是很久之前的事了",max_length=100,do_sample=True)
print(out)[{'generated_text': '这是很久之前的事了 曾 经 的 我 在 ktv 里 唱 了 一 首 儿 歌 , 这 首 歌 是 送 给 我 曾 经 的 她 , 不 知 道 她 是 不 是 很 会 写 歌 , 感 觉 自 己 在 偷 偷 写 信 给 她 , 她 已 经 很 久 都 没 有 我 了 , 她 已 经 好 久 都 没 有 我 了 , 我 一 直 很 挂 念 从 前 的 , 我 一 直 好 希 望 能'}]
中文文言文生成
#中文文言文生成
from transformers import BertTokenizer,GPT2LMHeadModel,TextGenerationPipeline
tokenizer = BertTokenizer.from_pretrained(r"/Volumes/Date/huggingface/model/gpt2-chinese/models--uer--gpt2-chinese-ancient/snapshots/3b264872995b09b5d9873e458f3d03a221c00669")
model = GPT2LMHeadModel.from_pretrained(r"/Volumes/Date/huggingface/model/gpt2-chinese/models--uer--gpt2-chinese-ancient/snapshots/3b264872995b09b5d9873e458f3d03a221c00669")
#device=0 指定当前的推理设备为第一块GPU;如果没有GPU环境,就去掉该参数
text_generator = TextGenerationPipeline(model,tokenizer,device=0)
out = text_generator("于是乎",max_length=100,do_sample=True)
print(out)[{'generated_text': '于是乎 神 曰 : 中 央 何 以 太 古 之 大 吕 为 宫 , 以 太 簇 之 律 计 自 乘 八 十 四 徽 至 六 十 一 徽 , 凡 五 徽 之 用 , 以 二 寸 为 商 , 上 为 无 射 之 商 , 下 为 无 射 之 商 , 应 钟 之 商 , 不 应 中 吕 之 商 , 应 钟 之 商 , 不 应 黄 钟 之 商 , 此 不 以 正 声 为 商 也 。 正 声 之'}]
中文对联生成
from transformers import BertTokenizer, GPT2LMHeadModel, TextGenerationPipeline
# 加载中文对联模型的 tokenizer 和模型
tokenizer = BertTokenizer.from_pretrained("uer/gpt2-chinese-couplet")
model = GPT2LMHeadModel.from_pretrained("uer/gpt2-chinese-couplet")
# 创建文本生成管道
text_generator = TextGenerationPipeline(model, tokenizer)
# 生成对联,以 [CLS] 为对联的开头
print(text_generator("[CLS]十口心思,思乡思国思社稷 -", max_length=28,do_sample=True))[CLS] 标记:特殊标记,用于标记对联的开头。生成的对联会以 [CLS] 为开头,模型将生成后续部分。
中文古诗生成
from transformers import BertTokenizer, GPT2LMHeadModel, TextGenerationPipeline
# 加载中文古诗模型的 tokenizer 和模型
tokenizer = BertTokenizer.from_pretrained("uer/gpt2-chinese-poem")
model = GPT2LMHeadModel.from_pretrained("uer/gpt2-chinese-poem")
# 创建文本生成管道
text_generator = TextGenerationPipeline(model, tokenizer)
# 生成古诗,指定古诗的开头部分
print(text_generator("[CLS]梅 山 如 积 翠 ,", max_length=50, do_sample=True))max_length=50 :设置生成文本的最大长度,确保古诗生成结果不超出指定长度。
文古诗生成格式
本地训练GPT-2中文模型个
训练数据集结构
在训练模型之前,需要准备好符合要求的数据集。例如, chinese_poems.txt 文件应该包含每行一首古诗。示例内容如下:
床前明月光,疑是地上霜。
举头望明月,低头思故乡。每行一首古诗:数据集中的每一行代表一个训练样本。数据的格式和内容直接影响模型的训练效果。
文件编码:确保文件使用 UTF-8 编码,以正确处理中文字符。
数据准备
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self):
with open("data/chinese_poems.txt",encoding="utf-8") as f:
lines = f.readlines()
#读取数据文件并去除每行的空白字符,确保数据清洁
lines = [i.strip() for i in lines]
self.lines = lines
def __len__(self):
return len(self.lines)
def __getitem__(self, item):
return self.lines[item]
if __name__ == '__main__':
dataset = MyDataset()
print(len(dataset),dataset[-1])训练模型
# 导入transformers库中的AdamW优化器
from transformers import AdamW
# 导入transformers库中的优化器调度器获取函数
from transformers.optimization import get_scheduler
# 导入PyTorch库
import torch
# 导入自定义的数据集类MyDataset
from data import MyDataset
# 导入transformers库中的自动分词器
from transformers import AutoTokenizer
# 导入transformers库中的因果语言模型和GPT2模型
from transformers import AutoModelForCausalLM, GPT2Model
# 实例化自定义数据集
dataset = MyDataset()
# 加载预训练的编码器(分词器)
tokenizer = AutoTokenizer.from_pretrained(r"D:\PycharmProjects\demo_16\model\models--uer--gpt2-chinese-cluecorpussmall\snapshots\c2c0249d8a2731f269414cc3b22dff021f8e07a3")
# 加载预训练的模型
model = AutoModelForCausalLM.from_pretrained(r"D:\PycharmProjects\demo_16\model\models--uer--gpt2-chinese-cluecorpussmall\snapshots\c2c0249d8a2731f269414cc3b22dff021f8e07a3")
# 打印模型结构(已注释)
# print(model)
# 定义数据预处理函数,用于将文本编码成模型所需的格式
def collate_fn(data):
# 使用分词器对数据进行编码,并添加必要的填充和截断
data = tokenizer.batch_encode_plus(data,
padding=True, # 填充序列
truncation=True, # 截断序列
max_length=512, # 最大序列长度
return_tensors='pt') # 返回PyTorch张量
# 创建标签,与输入ID相同
data['labels'] = data['input_ids'].clone()
return data
# 创建数据加载器,用于批量加载数据
loader = torch.utils.data.DataLoader(
dataset=dataset, # 指定数据集
batch_size=6, # 指定批量大小
collate_fn=collate_fn, # 指定预处理函数
shuffle=True, # 打乱数据
drop_last=True, # 如果最后一个批次不足,则丢弃
)
# 打印数据加载器中的批次数量
print(len(loader))
# 定义训练函数
def train():
global model # 使用全局变量model
# 确定使用CPU还是GPU
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# 将模型移动到指定设备
model = model.to(device)
# 实例化优化器
optimizer = AdamW(model.parameters(), lr=2e-5)
# 获取优化器调度器
scheduler = get_scheduler(name='linear', # 线性调度器
num_warmup_steps=0, # 预热步数
num_training_steps=len(loader), # 总训练步数
optimizer=optimizer)
# 设置模型为训练模式
model.train()
# 遍历数据加载器中的每个批次
for i, data in enumerate(loader):
# 将数据移动到指定设备
for k in data.keys():
data[k] = data[k].to(device)
# 前向传播
out = model(**data)
# 获取损失
loss = out['loss']
# 反向传播
loss.backward()
# 梯度裁剪,防止梯度爆炸
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
# 更新模型参数
optimizer.step()
# 更新学习率
scheduler.step()
# 清空梯度
optimizer.zero_grad()
model.zero_grad()
# 每隔50个批次打印一次训练信息
if i % 50 == 0:
# 准备标签和输出用于计算准确率
labels = data['labels'][:, 1:]
#通过‘logits’获取模型的原始输出值
out = out['logits'].argmax(dim=2)[:, :-1]
# 移除在数据预处理阶段添加的填充(通常是0),以便只计算实际数据部分的损失和准确率,避免填充部分对模型性能评估的影响。
select = labels != 0
labels = labels[select]
out = out[select]
del select
# 计算准确率
accuracy = (labels == out).sum().item() / labels.numel()
# 获取当前学习率
lr = optimizer.state_dict()['param_groups'][0]['lr']
# 打印批次索引、损失、学习率和准确率
print(i, loss.item(),lr, accuracy)
# 保存模型参数,不保存模型结构
torch.save(model.state_dict(), 'net.pt')
# 打印模型参数保存成功信息
print("权重保存成功!")
# 当脚本作为主程序运行时,执行以下代码
if __name__ == '__main__':
# 进行1000个训练周期
for epoch in range(1000):
# 调用训练函数
train()