什么是向量
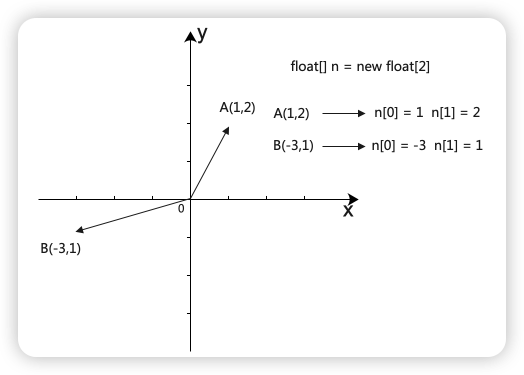
在数学中,向量(也称为欧几里得向量、几何向量),指具有大小(magnitude)和方向的量。二维平面中,一个向量表示xy坐标轴的坐标点 `A(1,2)`,在编程领域,一个二维向量对应的就是一个大小为二的float类型的数组。
文本向量化
文本向量化是指,利用大模型可以把一个字、一个词或一段话映射为一个多维向量。
在LangChain4j中向量模型OpenAiEmbeddingModel对话展示文本向量:
public static void main(String[] args) {
OpenAiEmbeddingModel embeddingModel = OpenAiEmbeddingModel.builder()
.baseUrl("http://langchain4j.dev/demo/openai/v1")
.apiKey("demo")
.build();
Response<Embedding> embed = embeddingModel.embed("你好,我叫风");
System.out.println(embed.content().toString());
System.out.println(embed.content().vector().length);
}
// 输出结果
Embedding { vector = [-0.010026788, -0.009126372, -0.0085925525, ......, -0.045200944] }
1536从结果可以知道"你好,我叫风"这句话经过OpenAiEmbeddingModel向量化之后得到的一个长度为1536的float数组。
基于向量来判断两句话之间的相似度。
1536是固定的,不会随着句子长度而变化
向量相似度
向量模型也是经过大量机器学习训练之后产生,向量模型效果与其对自然语言理解的程度成正相关。如果两句话对应的向量相似,那么就表示大模型对这两句话语义理解比较相似,在假设大模型的理解比较理性的情况下,就表示这两句话的意思越相近。
比如可以通过计算两个坐标的余弦相似度(代码是ChatGPT生成的):
public class CosineSimilarity {
// 计算两个向量的点积
public static double dotProduct(double[] vectorA, double[] vectorB) {
double dotProduct = 0;
for (int i = 0; i < vectorA.length; i++) {
dotProduct += vectorA[i] * vectorB[i];
}
return dotProduct;
}
// 计算向量的模
public static double vectorMagnitude(double[] vector) {
double magnitude = 0;
for (double component : vector) {
magnitude += Math.pow(component, 2);
}
return Math.sqrt(magnitude);
}
// 计算余弦相似度
public static double cosineSimilarity(double[] vectorA, double[] vectorB) {
double dotProduct = dotProduct(vectorA, vectorB);
double magnitudeA = vectorMagnitude(vectorA);
double magnitudeB = vectorMagnitude(vectorB);
if (magnitudeA == 0 || magnitudeB == 0) {
return 0; // 避免除以零
} else {
return dotProduct / (magnitudeA * magnitudeB);
}
}
// 通过向量的相近度近似计算语义的相似度
public static void main(String[] args) {
// 示例向量
double[] vectorA = {1, 2, 3};
double[] vectorB = {3, 2, 1};
// 计算余弦相似度
double similarity = cosineSimilarity(vectorA, vectorB);
System.out.println("Cosine Similarity: " + similarity);
}
}向量数据库
向量数据库可以存储向量模型生成的向量,就可以利用向量数据库来计算两个向量之间的相似度,或者根据一个向量查找与之相似的向量。
在LangChain4j中,EmbeddingStore表示向量数据库,它有20个实现类:
AstraDbEmbeddingStore
AzureAiSearchEmbeddingStore
CassandraEmbeddingStore
ChromaEmbeddingStore
ElasticsearchEmbeddingStore
InMemoryEmbeddingStore
InfinispanEmbeddingStore
MemoryIdEmbeddingStore
MilvusEmbeddingStore
MinimalEmbeddingStore
MongoDbEmbeddingStore
Neo4jEmbeddingStore
OpenSearchEmbeddingStore
PgVectorEmbeddingStore
PineconeEmbeddingStore
QdrantEmbeddingStore
RedisEmbeddingStore
VearchEmbeddingStore
VespaEmbeddingStore
WeaviateEmbeddingStore
使用Redis操作向量
首先添加依赖:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-redis</artifactId>
<version>${langchain4j.version}</version>
</dependency>注意普通的Redis是不支持向量存储和查询的,需要额外的redisearch模块,
使用docker来运行一个带有redisearch模块的redis容器`docker run -p 6379:6379 redis/redis-stack-server:latest`
存储向量到redis
RedisEmbeddingStore embeddingStore = RedisEmbeddingStore.builder()
.host("127.0.0.1")
.port(6379)
.dimension(1536)
.build();
// 生成向量
Response<Embedding> embed = embeddingModel.embed("我是风");
// 存储向量
embeddingStore.add(embed.content());
// 清空向量
redis-cli FT.DROPINDEX embedding-index DD匹配向量
使用“我的名字叫风”来查找到“我是风”
public static void main(String[] args) {
OpenAiEmbeddingModel embeddingModel = OpenAiEmbeddingModel.builder()
.baseUrl("http://langchain4j.dev/demo/openai/v1")
.apiKey("demo")
.build();
RedisEmbeddingStore embeddingStore = RedisEmbeddingStore.builder()
.host("127.0.0.1")
.port(6379)
.dimension(1536)
.build();
// 生成向量
Response<Embedding> embed = embeddingModel.embed("我的名字叫周瑜");
List<EmbeddingMatch<TextSegment>> result = embeddingStore.findRelevant(embed.content(), 4);
for (EmbeddingMatch<TextSegment> embeddingMatch : result) {
System.out.println(embeddingMatch.score());
}
}
// 执行结果
0.9765566289425
// 提示词换成:今天天气很好,执行结果
0.8937962949275看上去似乎分数差别不大,应该是小数位很多,分数精度比较高,两个分数还是有一定距离。
向量搜索
基于向量快速的得到和文本相似的文本
// 生成向量
TextSegment textSegment1 = TextSegment.textSegment("客服电话是400-8888888");
TextSegment textSegment2 = TextSegment.textSegment("客服工作时间是周一到周五");
TextSegment textSegment3 = TextSegment.textSegment("客服投诉电话是400-9999999");
Response<Embedding> embed1 = embeddingModel.embed(textSegment1);
Response<Embedding> embed2 = embeddingModel.embed(textSegment2);
Response<Embedding> embed3 = embeddingModel.embed(textSegment3);
// 存储向量
embeddingStore.add(embed1.content(), textSegment1);
embeddingStore.add(embed2.content(), textSegment2);
embeddingStore.add(embed3.content(), textSegment3);向量数据库中添加三条客户相关的知识,并且通过TextSegment把原始文本也存入了Redis,相当于Redis中现在存储了三条原始文本以及对应的向量,然后查询:
// 生成向量
Response<Embedding> embed = embeddingModel.embed("客服电话多少");
// 查询
List<EmbeddingMatch<TextSegment>> result = embeddingStore.findRelevant(embed.content(), 5);
for (EmbeddingMatch<TextSegment> embeddingMatch : result) {
System.out.println(embeddingMatch.embedded().text() + ",分数为:" + embeddingMatch.score());
}客服电话是400-8558558,分数为:0.9529553055763
客服投诉电话是400-8668668,分数为:0.9520588517189
客服工作时间是周一到周五,分数为:0.9305278658864999